定向采集教程
前序
采集规则编写对入门有一定难度,只要多尝试上手了后期使用起来会很方便,对今后使用其他采集软件也是多多受益
域名建站系统定向采集工具在网站后台的内容管理里
操作路径:
内容管理>采集管理>规则采集
设置 采集列表网址
列表网址就是您要采集的网站的栏目列表地址
如果只是单纯采集列表页的第一页,直接输入该列表URL就行,采集第一页的内容的好处就是可以不用采集老旧的新闻,而且有新更新也可以及时采集到。如果需要采集该栏目的所有内容,那也可以通过设置通配符的方式,匹配所有列表URL规则。
匹配URL规则的方法也很简单,你只需要查看列表分页的不同,加个通配符即可,以人民网科技频道为例:
第一页的URL是:http://scitech.people.com.cn/index1.html
第二页的URL是:http://scitech.people.com.cn/index2.html
第三页的URL是:http://scitech.people.com.cn/index3.html
通过观察列表URL的变化,可以看出第一页就是index1.shtml,第二页就是index2.shtml,第三页就是index3.shtml,变换的就是页码而已,列表页的URL通配符是 [开始页-结束页] ,假如你要采集栏目前10页的,那么列表URL规则就是:http://scitech.people.com.cn/index[1-10].html ,看到其中的区别了吧,就是在变换的部分加入通配符,从开始页到结束页即可。
设置 文章网址区域
上面我们已经设置了要采集的网站列表网址,但是打开这个网址页面有很多内容,程序无法知道哪些才是要采集的文章网址,所以我们这里要设置一个区域规则去告诉它。
如图所示,红色框内才是我们要采集的文章

这个规则怎么写呢,就是你写个规则告诉它文章网址从哪里开始,从哪里结束,最后写成规则就是
开始的地方的代码``[内容]``结束的地方的代码
比如我们打开上面人民网科技频道列表的第一页:
http://scitech.people.com.cn/index1.html
打开后,右键查看源码,通过查看源码找到我们要的那些文章网址的区域
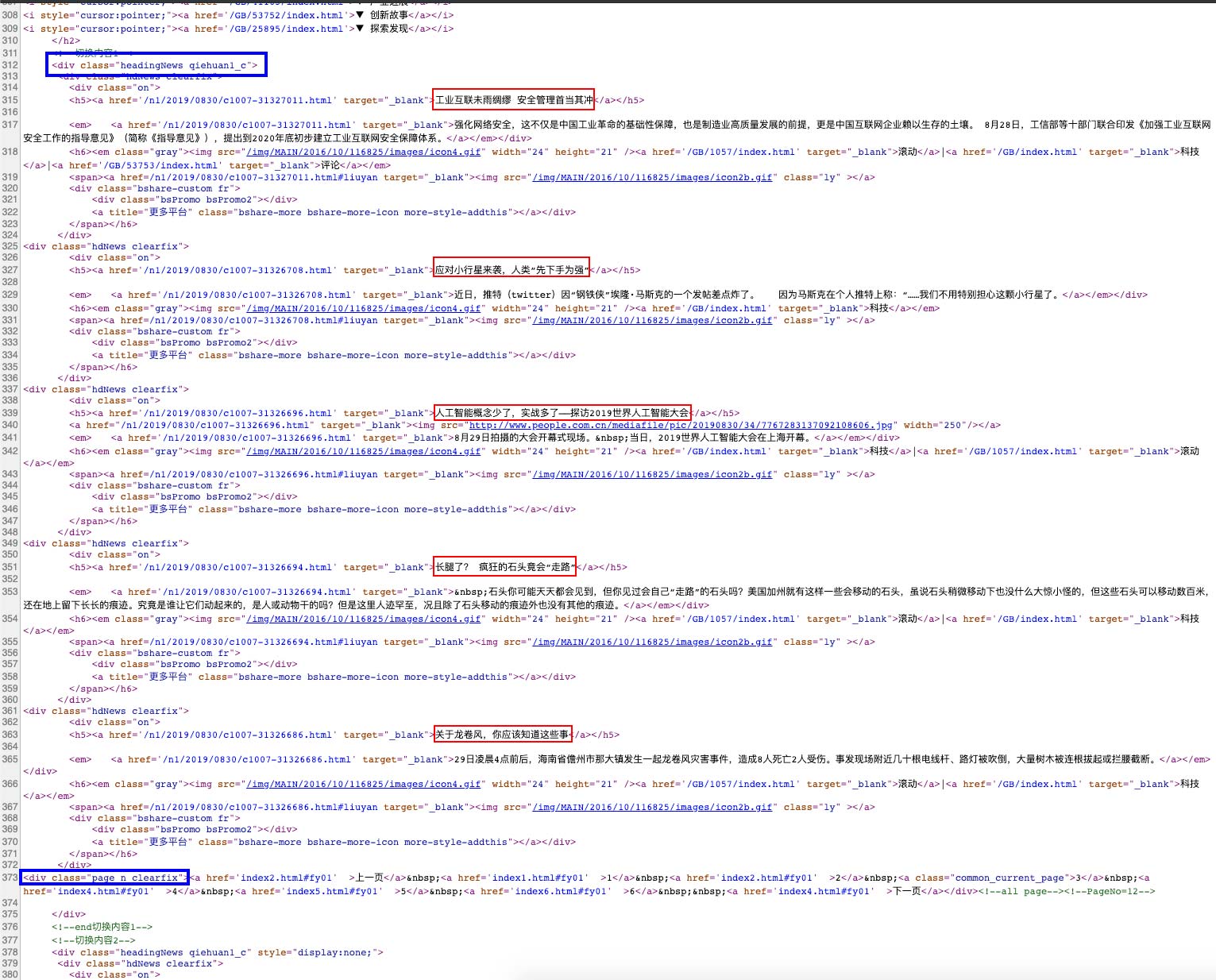
最后我们在前后找到一段唯一的代码做成规则,就是
<div class="headingNews qiehuan1_c">[内容]<div class="page_n clearfix">
设置 标题规则
标题规则和文章网址区域规则写法是类似的,打开列表里的任意一篇文章,查看源代码找到页面里含有标题的地方
如文章网址:http://scitech.people.com.cn/n1/2019/0830/c1007-31327011.html,源代码截图如下

标题前后一段唯一的代码做成规则,就是
<title>[内容]--科技--人民网 </title>
设置 正文规则
还是在上面的页面里找到正文所在的那个区域,找到正文前后的一段唯一的代码做成规则
如图所示

最后规则可以写成
<div class="box_con" id="rwb_zw">[内容]<div class="zdfy clearfix">
最后点击测试,如果测试成功了点击保存即可采集
